(OpenShift, Storage, Ceph, Security, Architektur)
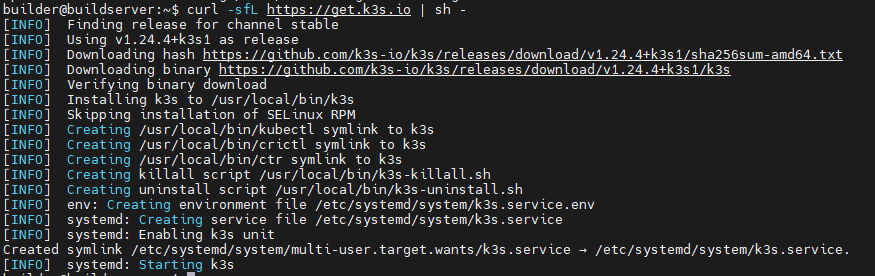
Wenn wir über stateful Workloads in Kubernetes sprechen, kommen wir an Red Hat OpenShift Data Foundation (ODF) kaum vorbei. Als Software-Defined-Storage-Lösung (basierend auf Ceph, Rook und NooBaa) bietet ODF die notwendige Persistenz für Container-Anwendungen.
Doch bevor das erste PVC (Persistent Volume Claim) erstellt wird, stehen Architekten vor einer entscheidenden Frage: Wie integrieren wir den Storage in den Cluster? Die Wahl der Deployment-Methode beeinflusst maßgeblich Skalierbarkeit, Kosten und Performance.
In diesem Beitrag werfen wir einen technischen Blick auf die zwei primären Betriebsmodi der Version 4.20 – Internal (Hyperconverged) und External – und bieten Ihnen eine fundierte Entscheidungshilfe.
1. Die ODF-Deployment-Modi im Detail
Red Hat ODF bietet Flexibilität, indem es entweder „im Bauch“ des OpenShift Clusters läuft oder eine externe Storage-Instanz konsumiert.
Internal Mode (Hyperconverged)
Im Hyperconverged-Modus laufen ODF-Storage-Pods direkt auf den OpenShift Worker Nodes. Compute (Anwendungen) und Storage (ODF) teilen sich dieselbe Infrastruktur.
- Architektur: Storage Devices (NVMe/SSD) werden direkt an die Worker Nodes durchgereicht. Der ODF Operator verwaltet den Ceph-Cluster als Container-Workload.
- Vorteil: Einfachste Installation über die OpenShift Console oder CLI. Ideal für eine schnelle Inbetriebnahme und Edge-Szenarien.
External Mode
Hier fungiert OpenShift lediglich als Client. Der ODF-Operator verbindet den OpenShift Cluster mit einem separaten Red Hat Ceph Storage (RHCS) Cluster, der auf dedizierter Hardware läuft.
- Architektur: Strikte Trennung von Compute und Storage. OpenShift konsumiert Speicher über das Netzwerk (RBD/CephFS).
- Vorteil: Unabhängigkeit und Entkopplung des Storage-Lifecycles vom OpenShift Cluster.
External Mode
Hier fungiert OpenShift lediglich als Client. Der ODF-Operator verbindet den OpenShift Cluster mit einem separaten Red Hat Ceph Storage (RHCS) Cluster, der auf dedizierter Hardware läuft.
- Architektur: Strikte Trennung von Compute und Storage. OpenShift konsumiert Speicher über das Netzwerk (RBD/CephFS).
- Vorteil: Unabhängigkeit und Entkopplung des Storage-Lifecycles vom OpenShift Cluster.
2. Entscheidungshilfe: Internal vs. External im direkten Vergleich
Welcher Modus ist der richtige? Diese Entscheidung hängt oft von der Größe der Umgebung, dem Budget und den Performance-Anforderungen ab. Hier ist ein direkter Vergleich, der Architekten bei der Planung unterstützt:
| Kriterium | Internal Mode (Hyperconverged) | External Mode (Standalone Ceph) |
| Zielgruppe | Edge, Dev/Test, kleine bis mittlere Produktions-Cluster. | Enterprise-Datacenter, Multi-Cluster Umgebungen und Petabyte-Scale. |
| Ressourcennutzung | Shared: ODF-Pods konkurrieren mit Applikationen um CPU/RAM. | Dedicated: Storage läuft auf eigener Hardware. Keine Ressourcenkonkurrenz. |
| Skalierbarkeit | Skaliert mit den OpenShift Nodes. Hoher Speicherbedarf kann höhere OpenShift-Lizenzkosten (Cores) verursachen. | Unabhängig: Speicher kann hinzugefügt werden, ohne die OCP Compute-Nodes erweitern zu müssen. |
| Wartung & Lifecycle | Simpel: Ein Upgrade-Zyklus. ODF wird mit OpenShift aktualisiert. | Entkoppelt: Ceph und OpenShift können unabhängig voneinander gewartet werden. |
| Multi-Cluster | Storage ist meist an einen Cluster gebunden. | Ein großer Ceph-Cluster kann Storage für mehrere OpenShift-Cluster bereitstellen. |
| Kosten (bei Scale) | Geringere Initialkosten, aber potenziell höhere TCO (Total Cost of Ownership) pro TB bei sehr großen Datenmengen. | Höhere Initialkosten (eigene Hardware), aber oft günstiger pro TB bei Skalierung. |

3. Spezialthema Sicherheit: Data-at-Rest Encryption mit HashiCorp Vault
Für regulierte Umgebungen reicht es oft nicht aus, die Keys für die Data-at-Rest Encryption einfach in Kubernetes Secrets zu speichern. Hier kommt die Integration eines externen Key Management Systems (KMS) ins Spiel.
Die Integration mit HashiCorp Vault
ODF 4.x unterstützt die Nutzung eines externen KMS, um Schlüssel zentral und konform zu verwalten. HashiCorp Vault ist hierbei eine gängige und robuste Lösung.
Die Vorteile der KMS-Anbindung:
- Trennung der Hoheit: Der Admin des OpenShift Clusters hat keinen direkten Zugriff auf den Master-Key.
- Compliance & Auditierung: Zentrale Key-Rotation, Audit-Logs und detaillierte Zugriffskontrollen werden im KMS verwaltet.
Die Konfiguration erfolgt durch die Hinterlegung der Vault-Adresse und der notwendigen Authentifizierungsdetails (z.B. über die Kubernetes Authentication Method von Vault) direkt im StorageCluster Custom Resource Definition (CRD). ODF kann dann die Keys für die Geräteverschlüsselung (Device Encryption) oder die PV-Verschlüsselung sicher aus Vault beziehen.
Wichtiger Hinweis für Architekten: Bei der Nutzung von Vault muss dessen Hochverfügbarkeit (HA) gewährleistet sein. Ist das KMS nicht erreichbar, können verschlüsselte Pods nach einem Neustart unter Umständen nicht auf ihre Daten zugreifen.
4. Fazit und Unsere Empfehlung
Die Wahl zwischen Internal und External Mode ist eine strategische Entscheidung, die die zukünftige Entwicklung Ihrer OpenShift-Plattform bestimmt.
- Wählen Sie den Internal Mode, wenn Agilität und eine einfache, konsolidierte Infrastruktur im Vordergrund stehen – ideal für kleinere bis mittlere Workloads und Edge-Szenarien.
- Wählen Sie den External Mode, wenn Sie massive Skalierbarkeit, Performance-Garantien und die Notwendigkeit haben, Storage über mehrere OCP-Cluster hinweg zentral zu verwalten.
Die Migration zwischen diesen Modi ist komplex. Investieren Sie daher Zeit in die initiale Planung, idealerweise mit einem erfahrenen Partner, der Sie durch die spezifischen Anforderungen der ODF 4.20 Dokumentation leiten kann.
Benötigen Sie Unterstützung bei der Architekturplanung Ihrer OpenShift Data Foundation?
Als spezialisierter IT-Dienstleister helfen wir Ihnen, die optimale ODF-Architektur für Ihre Enterprise-Workloads zu entwerfen und umzusetzen – von Hyperconverged-Setups bis zur komplexen KMS-Integration mit HashiCorp Vault. Sprechen Sie uns an, um Ihre OpenShift-Strategie zu besprechen.