Wir erstellen einen Buildserver für einen GitOps Mechanismus, der auf einer eigenen virtuellen Maschine gehostet werden kann.
Zielsetzung
Am Ende möchten wir, nachdem ein Git Push in einen bestimmten Branch durchgeführt wurde, eine Automatische Pipeline auf einem Build Server ausgeführt haben, der anschließend die Applikation auf einem Zielsystem deployed.
Plan
Wie wollen wir das nun erreichen? Zunächst beschaffen wir uns einen installierten Ubuntu Server 20.04. In meinem Fall habe ich diesen auf einem lokalen System als virtuelle Maschine installiert. Denkbar sind aber auch sämtliche Hosting- oder Cloudanbieter, bei denen man Ubuntu Server beziehen kann. Beispiele wären Hetzner, JiffyBox, Contabo oder Microsoft Azure.
Auf die Installation oder Beschaffung eines entsprechenden Ubuntu Servers gehe ich jetzt nicht näher ein.
Wenn der Server steht, wird ein K3S installiert. Das ist eine Kubernetes Distribution, die speziell für den Einsatz auf IoT oder Edge Devices konzipiert ist. Da unser Server auch in Zukunft alleine bleiben möchte, eignet sich K3S ideal für den Anwendungsfall.
K3S Installation
Wenn der Ubuntu Server (oder nach belieben auch eine andere Distribution) bereit ist, kann die Installation vom K3S durchgeführt werden. Das ist tatsächlich sehr einfach und beschränkt sich im wesentlichen auf einen Bash Einzeiler:
curl -sfL https://get.k3s.io | sh -Danach wird ein Bash Script ausgeführt, was uns alle nötigen Binaries herunterlädt und die Services anlegt.
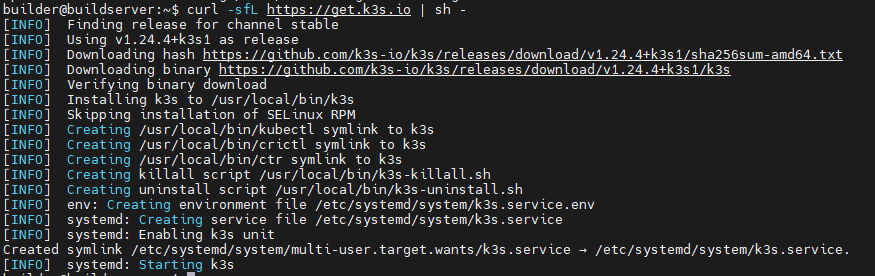
Danach wurde ein SystemD Service „k3s“ erstellt, der alle weiteren Prozesse für uns startet.
Die Dokumentation zum K3S ist hier zu finden: https://rancher.com/docs/k3s/latest/en/installation/install-options/
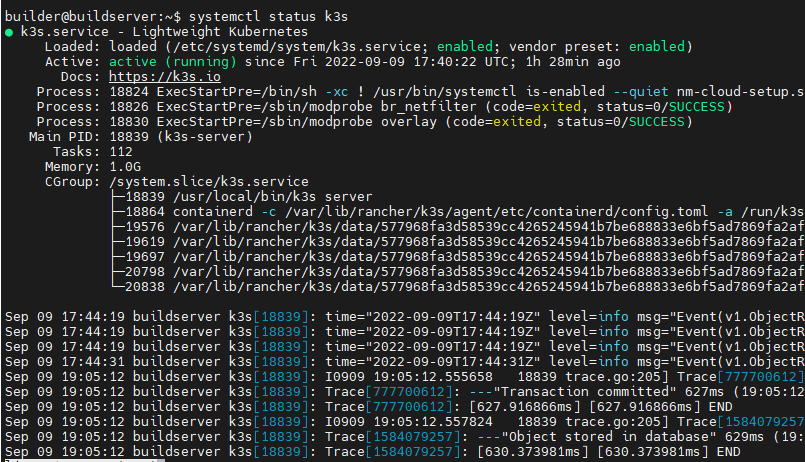
Nun können wir mit „kubectl“ auf den Cluster zugreifen.
sudo kubectl get nodeDie Cluster Config unter „/etc/rancher/k3s/k3s.yaml“ ist nur für root lesbar, deshalb müssen wir den kubectl Befehl mit sudo ausführen.

Tekton Installation
Für die Ausführung von Pipelines fällt meine Wahl auf Tekton. Das ist schön leichtgewichtig und bringt alles wichtige mit. Damit wir das auf den K3s Cluster installieren können, ist auch nur die Anwendung eines Kubernetes YAML nötig. Das sieht folgendermaßen aus.
kubectl apply --filename https://storage.googleapis.com/tekton-releases/pipeline/latest/release.yaml
Danach werden alle Kubernetes Ressourcen für Tekton im Cluster angelegt. Weiterhin wird ein neuer Namespace „tekton-pipelines“ erstellt, in dem die Ressourcen abgelegt werden.
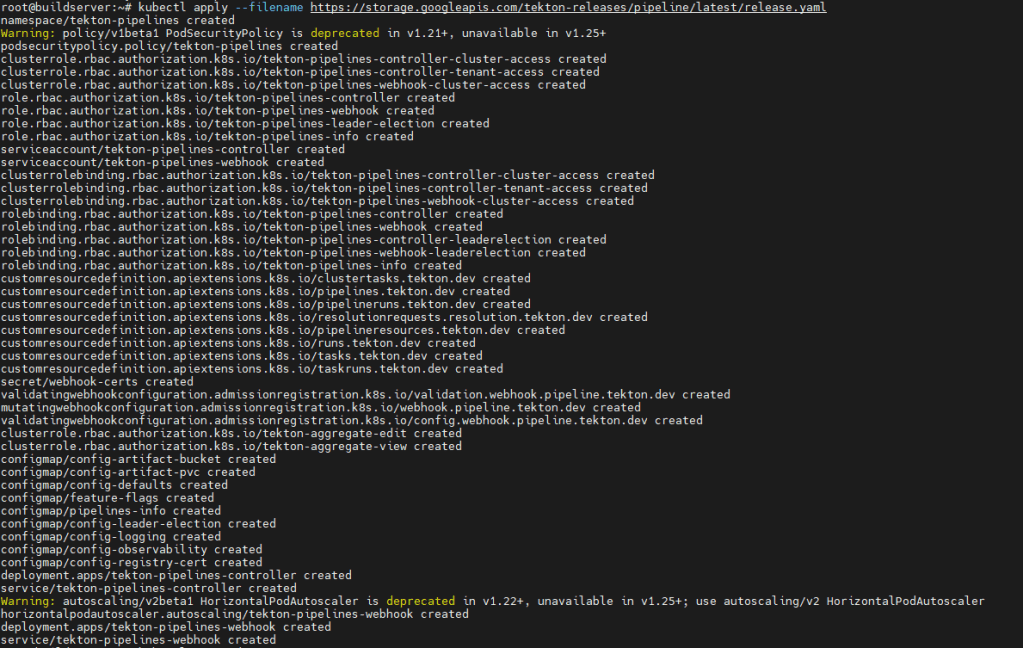
Die Dokumentation dazu ist hier zu finden: https://tekton.dev/docs/pipelines/install/
Wer Lust hat und einen besseren Überblick über die Tekton Pipelines haben möchte, kann anschließend noch das Tekton Dashboard installieren. Das funktioniert ähnlich wie die Installation der Tekton Pipelines.
kubectl apply --filename \
https://storage.googleapis.com/tekton-releases/dashboard/latest/tekton-dashboard-release.yamlDanach werden die entsprechenden Ressourcen im Cluster erstellt.
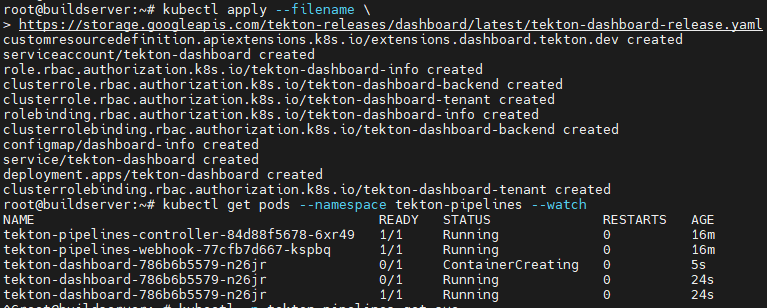
Danach wurde eine Service erstellt, der das Tekton Dashboard bereitstellt.

Da dieser allerdings nur als ClusterIP erstellt wurde, erstellen wir jetzt noch einen NodePort Service, der den gleichen Selector wie der ClusterIP Service bereitstellt. Dazu erstellen wir folgendes YAML File.
apiVersion: v1
kind: Service
metadata:
labels:
app: tkn-dashboard
name: tkn-dashboard
namespace: tekton-pipelines
spec:
ports:
- name: "9097"
port: 9097
protocol: TCP
targetPort: 9097
selector:
app.kubernetes.io/component: dashboard
app.kubernetes.io/instance: default
app.kubernetes.io/name: dashboard
app.kubernetes.io/part-of: tekton-dashboard
type: NodePort
Wir speichern die Datei unter dem Namen „tkn-dashboard.yaml“ und wenden es mit diesem Befehl an:
kubectl -n tekton-pipelines create -f tkn-dashboard.yamlDanach ist unser Service im Namespace „tekton-pipelines“ zu sehen:

So können wir nun auf das Dashboard per Browser zugreifen, indem wir unseren Server auf dem Port „30057“ aufrufen. Der Port kann variieren, da wir diesen in der Erstellung nicht festgelegt haben.
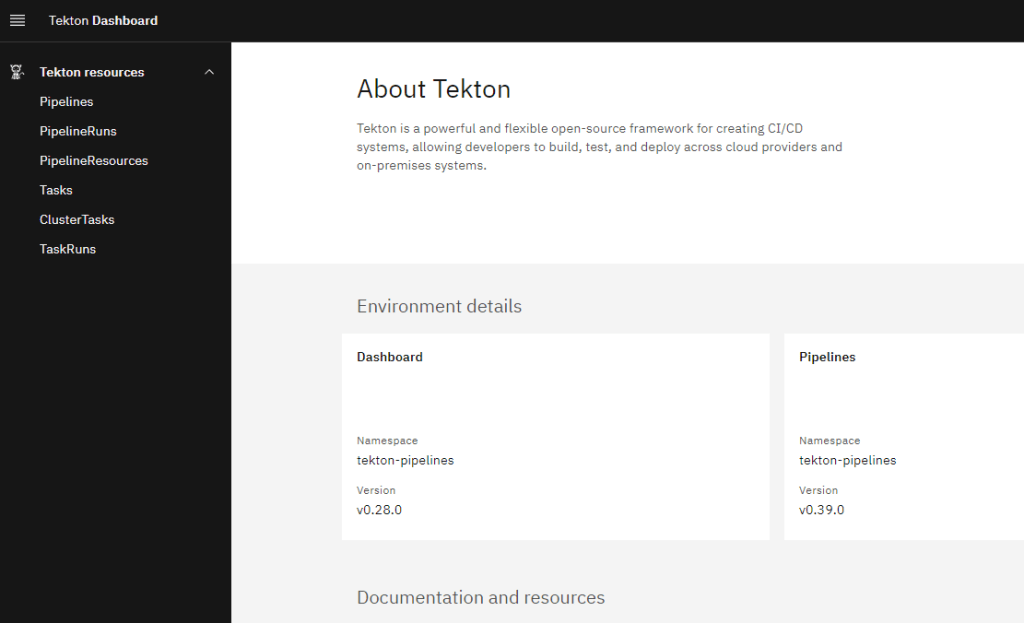
ArgoCD Installation
Nachdem nun unser CI Tool installiert ist, wäre es sinnvoll noch ein CD Tool zu installieren. Meine Wahl fällt auf ArgoCD, das sich dies gut mit Tekton kombinieren lässt und ich einfach schon die meiste Erfahrung damit habe.
Die offizielle Installationsanleitung könnt ihr hier finden: https://argo-cd.readthedocs.io/en/stable/getting_started/
Die Installation ist denkbar einfach, ähnlich wie bei Tekton muss ein YAML File auf dem Kubernetes Cluster angewendet werden:
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/core-install.yamlDanach werden alle nötigen Ressourcen im Cluster installiert.
Nun ist ArgoCD ebenfalls vorerst nur als ClusterIP zu erreichen. Also müssen wir zum erreichen des Dashboards auch hier einen NodePort Service erstellen. Die Definition sieht so aus:
apiVersion: v1
kind: Service
metadata:
labels:
app: argocd-dashboard
name: argocd-dashboard
namespace: argocd
spec:
ports:
- name: "8080"
port: 8080
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/name: argocd-server
type: NodePort
Die Datei nennen wir „argocd-dashboard.yaml“. Danach wird der NodePort Service mit folgenden Befehl erstellt:
kubectl -n argocd create -f argocd-dashboard.yamlWenn dieser erstellt wurde, können wir mit „kubectl -n argocd get svc“ den Status abfragen.

Nun können wir, in unserem Fall, über http://buildserver:32380/ auf das Dashboard zugreifen.
Um an die Zugangsdaten für den „admin“ Zugang im ArgoCD heranzukommen, geben wir folgenden Befehl ein:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echoDanach können wir uns im ArgoCD anmelden.
Nun wird es Zeit für ein praktisches Beispiel.
Die Applikation
Um eine Pipeline zu testen, habe ich eine Blazor Server Applikation, basierend auf dotnet 6 erstellt. Diese beinhaltet ein Dockerfile, was für die Erstellung eines Dockercontainers benutzt werden soll. Dieser soll dann anschließend auf unserem Kuberenetes Cluster deployed werden. ArgoCD könnte dabei auch einen anderen Kubernetes Cluster als Ziel für das Applikationsdeployment ansteuern. Der Einfachheit halber wird das aber auf dem vorhandenen K3S Cluster durchgeführt.
Um über ArgoCD eine Pipeline erstellen zu können, müssen wir als erstes die Pipeline für den Docker Build entwerfen. Dafür werde ich in dem Repository meiner Applikation einen Unterordner „tekton“ erstellen, in dem alle nötigen Pipeline Files liegen werden.
Eine gute Anleitung für den Start ist hier zu finden: https://tekton.dev/docs/how-to-guides/kaniko-build-push/
Mein Test Repository ist hier zu finden: https://github.com/saxonydevops/BlazorApp1
Die Build Pipeline
Um eine Tekton Pipeline laufen zu lassen, die einen Docker Container erstellt und diesen in ein Repository pusht, benötigen wir verschiedene Kubernetes Objekte.
- Pipeline
- PipelineRun
- PersistentVolumeClaim
- Secret
Die Pipeline sieht so aus:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: clone-build-push
spec:
description: |
This pipeline clones a git repo, builds a Docker image with Kaniko and
pushes it to a registry
params:
- name: repo-url
type: string
workspaces:
- name: shared-data
tasks:
- name: fetch-source
taskRef:
name: git-clone
workspaces:
- name: output
workspace: shared-data
params:
- name: url
value: $(params.repo-url)Der PipelineRun so:
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: clone-build-push-run
spec:
pipelineRef:
name: clone-build-push
podTemplate:
securityContext:
fsGroup: 65532
workspaces:
- name: shared-data
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
params:
- name: repo-url
value: https://github.com/saxonydevops/BlazorApp1.gitDamit der Push in unser Docker Hub Repository gelingt, müssen wir ein Secret mit den Zugangsdaten im Namespace anlegen, in dem unsere Pipeline ausgeführt wird.
Weiteres folgt in Teil 2….
